Deep learning approaches¶
The goal of these sections is to provide the theoretical underpinnings of deep learning models or deep neural networks (DNNs) commonly used for tempo, beat and downbeat tracking, to build an understanding of why these models work well in these tasks and what are their limitations. Here we discuss the main concepts and definitions, but for those interested in reading more about the use of DNNs in audio processing and MIR related tasks, we suggest them to take a look at works like McFee [McF18], Purwins et al. [PLV+19] and Choi et al. [CFCS17].
The field moved quite fast these past years and the amount different design choices and approaches can be somehow overwhelming! We tried to come up with a way of summarizing the different moving parts of beat and downbeat deep learning systems to help digest this, as we explain below.
Recent beat and downbeat tracking approaches can be structured in three main stages: 1) A first stage of low-level feature computation or feature extraction, where feature vectors that represent the content of musical audio are extracted from the raw audio signal (e.g. Spectrogram, Chromagram); 2) A second step that usually consists of a stage of feature learning, whose outcome is an activation function that indicates the most likely candidates for beats and/or downbeats among the input audio observations; 3) Finally, a post-processing stage is often used, usually consisting of a probabilistic graphical model which encodes some relevant musical rules to select the final beat/downbeat candidates.

Fig. 10 General pipeline commonly used for beat and/or downbeat tracking systems.¶
Different alternatives were proposed for the distinct stages among beat and downbeat tracking systems. Here we give an overview of the main ideas presented in the literature.
Feature extraction¶
It is common to exploit music knowledge for feature design using signal processing techniques. The three most explored categories of musically inspired features in the literature for both beat and downbeat estimation are: chroma (CH) [FMC+19, FMC+18, HDF12, KFRO12, KBockDW16, PP10a, PP10b] —used to reflect the harmonic content of the signal—, onset detection function (ODF) [DBDR15, HDF12, ZDGomez14] or spectral flux (SF) [FMC+19, FMC+18, HKS14, KFRO12, KBockW13] —as event-oriented indicators— and timbre inspired features [DDR14, HDF12, SHS14] such as spectral coefficients or MFCCs. For beat, the main features exploited are those related to event-oriented indicators, assuming that changes in the spectral energy relate to beat positions are [DRuaP+12, FJDE15, HKS14, KBockW13, KHCW15, NRJB15, SHCS15]. For downbeat, harmonic-related features showed to be relevant to estimate downbeats reliably across music genres.
The feature extraction is usually based on a single feature [BockKW14a, HKS14, KBockW14, KBockW11, PP10a, PP10b, SHCS15, ZDGomez14], with some exceptions exploiting more than one music property at the same time [DBDR15, DBDR16, DBDR17, FMC+19, FMC+18, KBockDW16, ZDGomez14], which results in systems robust to different music genres [DBDR17]. Recently, approaches based on deep learning exploring combinations of logarithmic spectrograms with different resolutions showed to perform competently [BockD20, BockDK19, BockKW16, KBockW14].
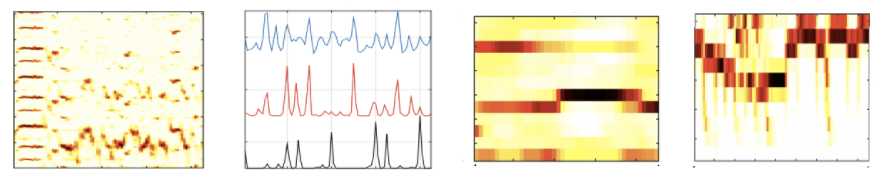
Likelihood estimation¶
The objective of this stage is to map the input representation into a beat/downbeat likelihood that indicates which are the most likely candidates to be a beat or a downbeat in a given temporal sequence. There are two main groups of approaches in this respect: the first one uses “heuristics” to perform the mapping, while the second group exploits machine learning approaches. The latter group is the most popular one in the literature in the last years and also the state of the art.
The estimation of a likelihood with heuristics is performed differently depending on the features used. For instance, a common approach is to pre-define a template of expected features such as spectral-flux or chroma, and to measure the distance between this template to the features computed from the audio signal [NRJB15, PP10b]. Within the group of machine learning approaches, we could identify two subgroups: a first one that exploits “traditional” learning techniques and a second one with focus on deep learning models.
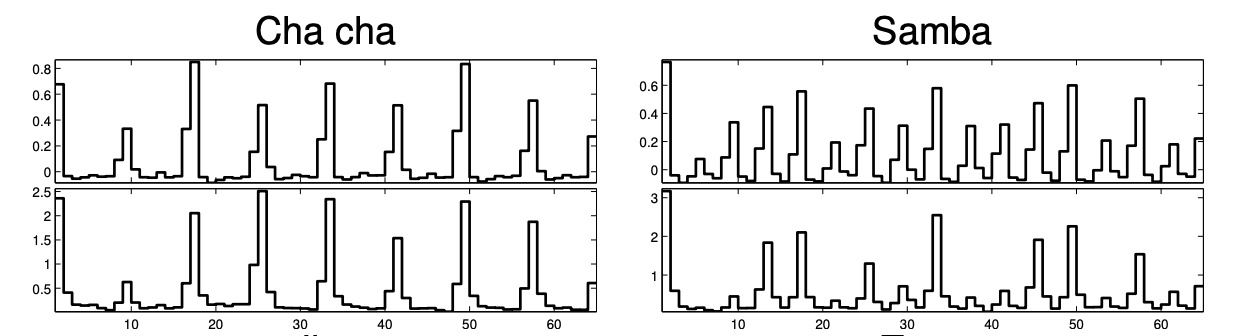
Before deep learning, machine learning systems often focus on recognizing rhythm patterns in data, for instance by using Gaussian Mixture Models (GMM) and k-means [HKS14, KBockW13, KHCW15, NRJB15, SHCS15, SHCS16, SHS17]. This usually required making some assumptions of style or genre (e.g. to define the length of the patterns to be learned), and for these models to be effective the music should have distinctive rhythmic patterns. Deep learning approaches propose an alternative to such limitations given their capacity to learn complex function mappings, and systems exploiting DNNs have became the state of the art in recent years [JLL19].

Inference¶
The aim of this stage is to obtain the final downbeat sequence by selecting the most likely candidates in the downbeat likelihood given some model or criteria. Probabilistic graphical models (PGMs) are the most used post-processing techniques since 2010. This might be due to two main reasons: PGMs offer a flexible framework to incorporate music knowledge and then exploit interrelated structure [PP10a, PP10b], and the Bar Pointer Model (BPM) [WCG06] stands as a very effective and adaptable model for meter tracking, being popular for beat and downbeat tracking.
PGMs proved to be adaptable to cultural-aware systems in diverse music cultures [HKS14, NRJB15, SHS14], being for instance extendable to track longer meter cycles and different meters than the widely explored 3/4 and 4/4 [SHCS16, SHS17]. Considerable efforts have been made towards improving the use of these models in practice, by reducing computational cost via an efficient state-space definition [KBockW11] or proposing sequential Monte Carlo methods (also called particle filters) for inference [KHCW15, SHCS15].
Next¶
After discussing the usual pipelines of beat and downbeat tracking systems, let’s dig a bit more in the different deep learning architectures used for likelihood estimation these past years.